I had the pleasure of working with an application (referred to in the blog as APPX) that could use some serious TLC about a month ago. Apperently APPX is in wide use by isurance agencies and brokers. I 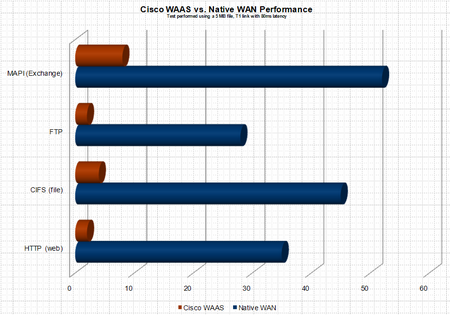 now know more about the interworkings of APPX than I want to know – and for the life of me can not figure out why the heck anyone would write an enterprise application ontop of the JET database, the answer I was given by the application developer is not everyone has MS SQL Server? OK – but if you are small enough not to have MS SQL Server (BTW – thats pretty freakin small) download MSDE it is free – or better yet why not use MySQL, Postgres, etc… anything but JET – ODBC, JDBC people it’s not 1972 :(. Here is how the saga began. A customer of ours was looking to remove file servers and print servers from 8 branch locataions. The articulated applications were standard CIFS shares and print services – a perfect fit for Cisco WAAS (Wide Area Application Services), a product which uses WAN accerleration technology and caching to remove WAN latency thus providing LAN like performane over the WAN.
now know more about the interworkings of APPX than I want to know – and for the life of me can not figure out why the heck anyone would write an enterprise application ontop of the JET database, the answer I was given by the application developer is not everyone has MS SQL Server? OK – but if you are small enough not to have MS SQL Server (BTW – thats pretty freakin small) download MSDE it is free – or better yet why not use MySQL, Postgres, etc… anything but JET – ODBC, JDBC people it’s not 1972 :(. Here is how the saga began. A customer of ours was looking to remove file servers and print servers from 8 branch locataions. The articulated applications were standard CIFS shares and print services – a perfect fit for Cisco WAAS (Wide Area Application Services), a product which uses WAN accerleration technology and caching to remove WAN latency thus providing LAN like performane over the WAN.
The plan was to migrate the data from the 8 branch locations to a core location (the datacenter) and have the users access the data over the WAN. The customer would then be able to remove the server infrastructure and all associated management from the edge locations. Does not get any simpler than this, or so we thought.
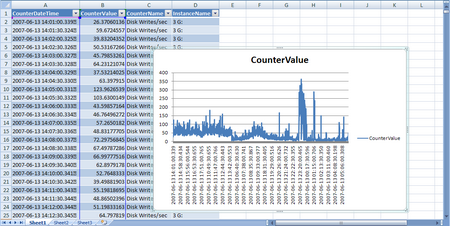
A bit of background information. The depoloyment model for the CISCO WAAS gear was to use WCCP NOT inline cards to route the appropriate traffic through the WAE. Pretty early in the process we realized that the end users sitting in the remote location and accessing a SMB/CIFS share in core location were expeiencing huge delays from within the APPX, which was run from a network share and sort of a hyrbid client/server/web application. Fast forward 3 weeks, I finally show up on site to try and resolve a ghostly performance issue. At this point acceleration and caching of FTP, HTTP, CIFS, etc… had been fully vetted and verified as working properly. BUT APPX was still expreiencing significant performance issues. Immediately I began to believe it was an application specific issue – in the end the assuption was correct but lets explore how we identified the issue.
Step 1: Contact the application developer and understand exactly 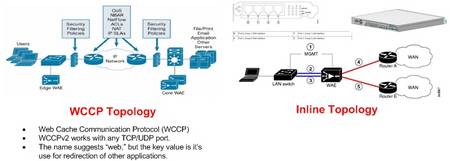 what the application does and the chronology of the steps.
what the application does and the chronology of the steps.
The following are the notes/bullets taken away from the conversation with APPX developer:
- Documents produced and mdb files can in fact be stored on different paths – the applcation uses a .mdb (JET database – HINT #1 PROBABLE LOCKING ISSUE) and .dot word templates to create form letters.
- When APPX creates files it prefixes the documents with “s” or “m” – “S” refers to schedule and M refers to memo
- APPX also suffixes the document with a numeric value – this value is the record locator
- The path to templates and proposals are stored in proposal.mdb
- Document locataions are strored in APPX personalization
As I mentioned above the APPX installation including the .dot and .mdb files were stored on a network share.
Step 2: Plan of attack
- Test the performance with the APPX folder (application) stored on the to local path (c: root) – Run wizard.exe to change the path
- Write the new template path. Writes the template path to the proposal.mdb
- If this worked the path changes could be changed via the registry. Which meant that we could automate the changes so that the users will not need to run the wizard.exe process. This will simplify a complete rollout of the local APPX installation.
NOTE: Currently (prior to the WAAS deployment) when a new template is created the APPX directory is robocopied to network shares at the 8 remote locations. The new process would be to use a login script to copy the APPX install to the local workstations when an change is made. Pre-positioning could be used in this case to increase the prerformace of the initial load. Not only will this solve the performance issue but it also represents a significant improvement to the currrent process. The automation of updating the templates using login scripts removes the robocopy responsibility from the IT staff and ensures that the users are always operating from the latest database and templates.
NOTE: reg key location for the APPX ditro directory – HKCU/Software/APPX/
Step 3: The actions taken to resolve the issue
Creation of scripts listed below to automate the required changes:
- update_distro.bat – creates APPX distribution as appxload.exe
- logon.bat – user logon script (encompasses commands from upappx.bat and regchg.bat)
- upappx.bat – Standalone script to updates users local c:\appx install
- regchg.bat – Standalone script to modifies APPX db directory location reg key
- appx_redirect_to_C.reg – reg key
All scripts housed in centralized network location ie \\core\share\waas_appx_scripts.
The logon scripts are located at \\core\netlogon
Ultimately to increase the speed of APPX the APPX Word document templates and mdb lookup databases will be moved from \\core\share\appx\database to c:\appx\database on the users localhost.
These changes dramatically increased the performance of the APPX, the belief is that performance problems were due to jet database related locking and lock release issues that were worsened due to WAN latency. During the automation process I did in fact verify that locks are placed on mdb files on a fairly regular basis. Initially I was told by the application developer, that the mdb files are not changed and locks are not placed on these files but this is not the case. Interestingly enough the APPX folks stated that most users are going to a more distributed model vs. a consolidated model. After understanding the application architecture it is not hard to understand why.
The process going forward would be the following is the following:
- Users in core will continue to run from the LAN location – While performance could probably be faster if they followed the same deployment model as listed above because the LAN locking is most likely slowing performance the application response time is adquate so it was decided that it would be left as is.
- There is a single administrator in the core location who modifies the templates – this typically happens weekly but may happen more frequently
- In the past these changes would be robocopied by IT to local shares in each remote office on Sunday nights. The new automated user update process removes the need for IT to manage the distribution of the APPX changes on a weekly basis. Users will now have access to updated APPX on a daily basis vs. weekly. Updates will be performed when the user logs in.
- There is now a scheduled task that has been created on \\core that performs the following tasks:
- The scheduled task name is appx_load
- Copies the APPX directory from d:\share\appx to d:\share\waas_appx_scripts\appx
- This step is required because there are locks on the mdb files in the \\core\share\appx directory and the files were skipped by 7z during compression.
- Once the copy of APPX is complete the APPX directory is packed into a self-executable 7z files name appxload.exe
- The scheduled task runs at 2AM S,M,T,W,T,F
- The appx_load scheduled task runs update_distro.bat which contains the following two commands:
- xcopy /e /y d:\share\appx d:\share\waas_appx_scripts\appx
- “c:\program files\7-zip\7z.exe” a -sfx appxload d:\share\waas_appx_scripts\appx
- This step is required because the compressed file transfer is far faster than using robocopy to update the users local APPX installation.
- The logon.bat script has been modified to copy the appxload.exe to c:\appxload.tmp on the users local machine
- Next appx.exe is run and unpacks the the APPX distribution to c:\appx
- NOTE: There is no measurable difference in user logon time. The customer is very happy with the process
- NOTE: The robocopy process was taking between 4 minutes for the initial copy and 30 seconds for updates
- Last the logon script modifies the db directory reg key to point to the new appx location
- The commands that are run in the logon.bat are also separated into two standalone .bat files
- upappx.bat and regchg.bat
NOTE: 7-Zip has also been installed on the \\core server and is required
NOTE: Once all the users have logged on and their reg keys modified the regedit command can be removed from the logon.bat script.
Script Details:
logon.bat:
rem update local APPX distro
@echo off
mkdir c:\appxload.tmp
copy \\core\share\waas_appx_scripts\appxload.exe c:\appxload.tmp
c:\appxload.tmp\appxload.exe -oc:\ -y
rem update APPX reg key
regedit.exe /s \\core\share\waas_appx_scripts\appx_redirect_to_C.reg
update_distro.bat
xcopy /e /y d:\share\appx d:\share\waas_appx_scripts\appx
“c:\program files\7-zip\7z.exe” a -sfx appx d:\vol15\waas_appx_scripts\appx
appx_redirect_to_C.reg
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\APPX]
“Database Directory”=”c:\\APPX\\DATABASE\\”
upappx.bat
@echo off
mkdir c:\appxload.tmp
copy \\core\share\waas_appx_scripts\appxload.exe c:\appxload.tmp
c:\appxload.tmp\appxload.exe -oc:\ -y
regchg.bat
regedit.exe /s \\core\share\waas_appx_scripts\appx_redirect_to_C.reg
So that more detail than I thought I would write. Obviously the actual application is not listed in the blog, but if you are interested in that app please send me an Email rich@bocchinfuso.net. I would be more than happy yo share more of the detail with you. Also if you find any typos, etc… in the post please leave a comment.
BTW- The customer has now been running for about 30 days and they are happy with the performance.