
One of my customers who was running three replication technologies, XOsoft, PlateSpin and EMC MirrorView started experiencing issue when we relocated their DR equipment from the production facility where we staged and tested the applications to their DR location.
While having the Producion and DR environments on the LAN we successfully replicated Exchange with XOsoft, Operating Systems with PlateSpin and Data with MirrorView, once we moved DR infrastructure these components all failed. This prompted us to perform network remediation. The following are the results of a simple ping test that was performed using WinMTR.

The above chart shows the output from output from a simple test which shows packets, hops, latency and % packet loss. We ran this tests a number of times from different source and destination hosts with similar results. The originating host for this for this host was 192.168.123.6 in the chart below 192.168.120.1 is the first hop.
NOTE: the destination 192.168.121.52 was sent 414 packets but only received 384 (NOTE: this number worsens over time). This is consistent with the behavior that XOsoft, PlateSpin and MV are experiencing.
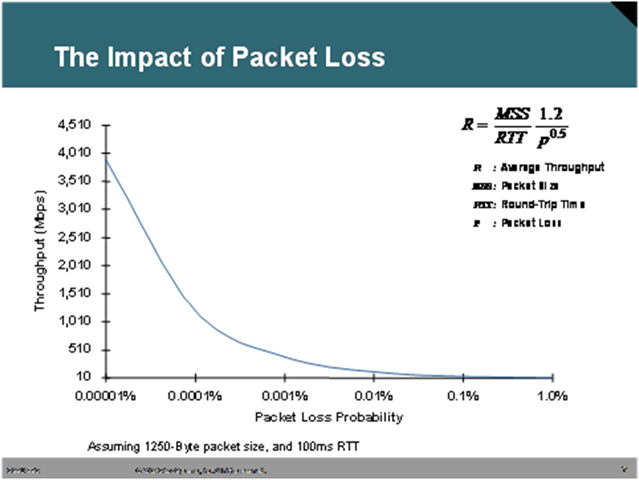
The graph below represent the impact of packet loss on bandwidth. As you can see 1% packet loss has a dramatic affect on relative bandwidth.
Using a bandwidth calculator found here http://www.wand.net.nz/~perry/max_download.php, we calculated the relative bandwidth using the metrics we observed.
- An effective speed of ~ 30KB/s was calculated using 7% packet loss, a 10Mbit link and 90ms RTT
- with 15ms RTT the effective speed is ~ 185 KB/s
- An effective speed of ~ 128KB/s was calculated using 1% packet loss, a 10Mbit link and 90ms RTT
- with 15ms RTT the effective speed is ~ 700 KB/s
These number are dramatic when compared to the expected 9 Mbit or 1152 KB/s
In conclusion a clean network is critical, especially with technologies like replication that rely on little or to no packet loss and the use of all the bandwidth available. Interestingly enough we seem to be seeing these sort of problems more and more often. My hypothesis is that more and more organizations are looking to implement DR strategies and data replication in a critical component to these strategies, understanding this I believe this problem will get worse before it gets better. For years many of these organizations have used applications and protocols which are tolerant of packet loss, congestion, collisions, etc… protocols like http, ftp, etc… Data replication technologies are far less forgiving so network issues that have most likely existed for sometime are rearing their head at inopportune times.
I’m a little curious about the math behind this. While I believe I
understand the methodology for the equation (though I’m not sure on
the 1.2), the values for throughput seem to be an order of
magnitude off. No matter how I do the math, at .00001% I see a
throughput of 379,473,319bps or 361.89Mbps, and by 1% I see
379,473bps or .36Mbps. Judging from the image, it appears that this
test yielded a 3,800Mbps throughput at .00001% (aprox.) The way I
see it, in the case of the .00001% probability of packet loss, the
math would be: Throughput in bits/sec = ((1,250 * 8)/(100 / 1000))
* (1.2 / (.00001 / 100)^.5) So is there a discrepancy in the image,
or in my math?