Greetings from VMworld 2018, my first VMworld in many years. To be honest, VMware had become like milk for me, couldn’t afford to not carry it in the convenience store, functioning as the catalyst for nearly every customer visit, but as the proprietor, my hope was that the patron who walked through the door looking for milk would buy some of my homemade Ho-Hos or better yet they showed up to buy milk at my convenience store because they couldn’t resist my homemade Ho-Hos. It’s always been my opinion that the tech business we are in is evolutionary and certainly Darwinian. “The Innovator’s Dilemma” in the context of first-movers and fast-followers has never been more relevant, we live in a world where the duality of cost and capability needs to be carefully managed, the subscription economy makes this delicate balancing act even more complex. Innovations early to market, the wrong balance of capability and cost become good ideas that die only to re-emerge at a time when the market is ready and the capability and cost balance is right. Most have heard the phrase “Imitate to Innovate”, or the idea that there are no original ideas, we live in a world of idea refinement, but there’s a twist called purpose. The paper straw was invented in 1888, we replaced it with the plastic straw because the paper straw sucked (no pun intended); guess what, the paper straw is back and it still sucks. I don’t really know what a paper straw in 1888 was like, the ones in 2018 suck pretty bad, so I wonder how much worse they could have been. While I am not sure when we replaced the paper straw with the plastic straw, I am pretty confident that our ability to thinly extrude a polymer gave us what seemed to be a better answer; the plastic straw was born and the paper straw was gone. So what’s different? We live in a purpose-driven society; this is what’s different. We are now willing to deal with a straw that falls apart in favor of the sustainability of our planet, some might say we are maturing. What does this have to do with VMworld or technology in general? It has everything to do with the consumer condition and the consumer condition creates a certain type of demand which is fulfilled by suppliers, it’s a simple model that impacts every sector. Purpose matters more than ever before and we live in a subscription economy, in enterprise information technology we call this subscription economy “The Cloud”, we measure purpose with things like carbon footprint and philanthropy, and we translate this into outcomes or economic value delivered. Outcomes like lower power consumption = lower power costs = lower carbon emissions; a financial win for the business with purpose. The technology is great stuff, but the velocity of innovation is driven by a purpose and the outcomes have a multifaceted deeper meaning. The purpose is the awesomesauce.
Let’s start with Pel Gelsinger’s (CEO, VMware) “Technology Superpowers” keynote on day one. Gelsinger starts by wishing VMware a happy 20th birthday, paying homage to the VMware community, the passion, loyalty and what he terms almost cult-like behavior. This is followed by a video montage which highlights VMware’s corporate culture showcasing a culture of innovation, passion, and commitment. Gelsinger finishes his opening by displaying his commitment with a VMware tattoo (obviously a temporary tattoo, but you get the idea).

Gelsinger’s close to his “Technology Superpowers” keynote on day one is an “I believe…” monologue that would make Simon Sinek proud.
- “Together we have the opportunity to build on the things that collectively we have done over the last four decades and truly have a positive global impact.”
- “I believe together we can successfully extend the lifespan of every human being.”
- “I believe together we can eradicate chronic diseases that have plagued mankind for centuries.”
- “I believe we can lift the remaining 10% of humanity out of extreme poverty.”
- “I believe that we can reskill every worker in the age of the superpowers.”
- “I believe that we can give modern education to every child on the planet; even in the remotest slums.”
- “I believe that together we can reverse the impact of climate change.”
- “I believe that together we have the opportunity to make these a reality.”
- “I believe that this possibility is only possible together with you.”
Gelsinger starts with why and ends with why, driving home the idea that purpose matters most.
Gelsinger answers the question of “Why VMware” from the “Why” choose VMware perspective and “Why” there is a purpose imperative that is deeper than a hypervisor. Well done!
Let’s move on to the day two and Sanjay Poonen’s (COO, Customer Operations, VMware) “Possible Begins With You” keynote, this is going to blow your purpose-driven mind. Gone are the days of the sports superstar on stage talking about what it takes to win, because we’re trying to win on a totally different level now, a far more complex level, a level with true purpose, a level that brings more than one tear to your eye, a level of bravery and inspiration that you can feel course through your soul. More on this later.
Sanjay Poonen opens with his commitment to the VMware culture by showing his dual tattoos. Sanjay spends time talking about the engines that fuel VMware, innovation and customer obsession. Stating that innovation and customer obsession are what are core to VMware, core to the culture. Sanjay then moves on to the economic value (the outcome) that VMware has delivered, stating that the ~ 50 billion in VMware revenue has delivered ~ 500 billion in economic value.
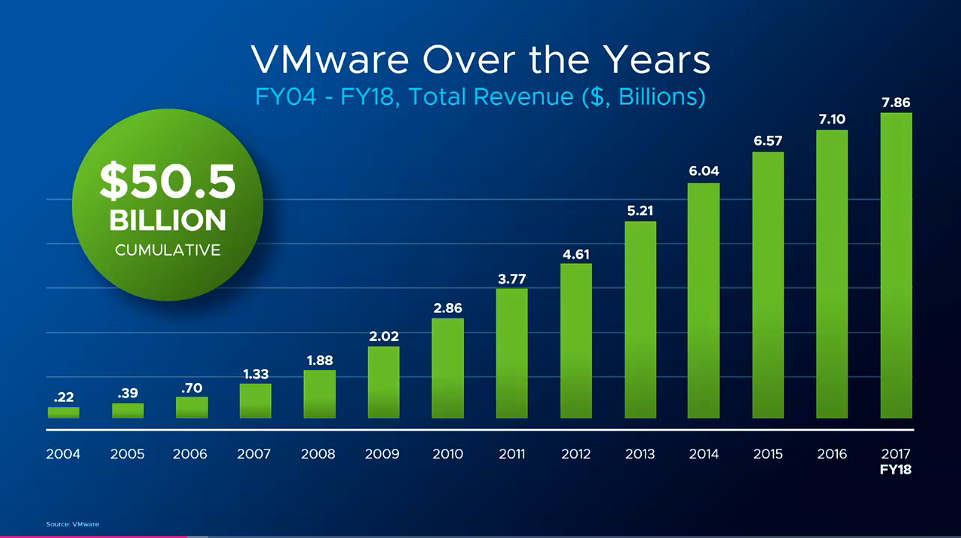
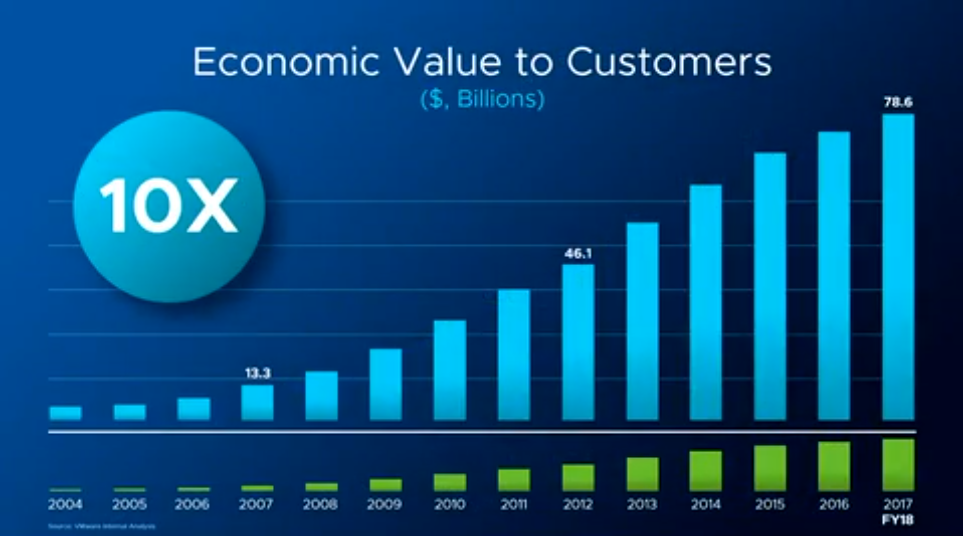
The Technology Superpowers of Cloud, Mobile, AI/ML, Edge/IoT are the “What”. IMO “What?” is the easiest question to answer. The difficult question is always “Why?” and the most compelling answer is always the answer to the question “Why?” VMware did a good job of painting the picture of “How”, and asking and answering the question of “Why?” Creating a message with a purpose that is about more than the infrastructure or software, it’s about how the infrastructure will provide a foundation that will allow us to transform our lives.
The fireside chat between Sanjay Poonen and Malala Yousafzai was truly amazing. The talk touched my soul, so much so that it feels irreverent for me to try to summarize this amazing young woman’s journey, her incredible perspective and her impact on the world using my words. We live in a time where purpose can limit our perspective and cloud (no pun intended) our judgment, but Malala has elevated herself to a place filled with love, acceptance and a desire for change, not judgment and hate. To hear her speak about her experiences and her perspectives was truly an honor and perspective-altering experience for me and I imagine it was for the nearly 25,000 in attendance (this is my hope). I am very thankful for having had the opportunity to be present.
Okay, so let me pull this back to a place where I don’t have tears in my eyes. My main reason for being at VMworld this week was to continue to shepherd our relationship with OVHcloud, a partnership that I believe will help our customers (FusionStorm’s, OVHcloud’s and VMware’s) transform their businesses in such a way that they can focus on their core business, increase agility and reduce risk. Pat Gelsinger’s Technology Superpowers of Cloud, Mobile, AI/ML and Edge/IoT all have something in common, they are superpowers which have a clear line of sight to business and economic value.
What’s great about the subscription economy is it provides us (the consumer) with the ability to get what we want when we want it, in an agile and elastic delivery model. We have instant access to the assets, but we don’t have to be the custodian of these assets, we have the elasticity to increase, contract or terminate our subscriptions based on our needs or constraints. The subscription economy is everywhere, it’s a consumer condition, and consumers make up the enterprise. When I think about FusionStorm and OVHcloud I have a clear vision of what we can deliver to the market, together, and it looks something like this:
OVHcloud builds and operates data centers. They deliver Infrastructure-as-a-Service (IaaS) in an agile, elastic and fully automated way. OVHcloud provides a strong foundation for the IT infrastructure subscription economy, this is OVHcloud’s core business, and they do it really well. OVHcloud provides FusionStorm the “Freedom to Build and the Freedom to Innovate” business solutions on behalf of our collective customers on a market leading IaaS platform.

FusionStorm takes cloud-based infrastructure provided by OVHcloud as either HPC (Hybrid-Private Cloud) or bare metal and builds, delivers and operates business Platforms-as-a-Service that deliver the right mix of cost and capability to meet the customer requirements. Delivering the business Platform-as-a-Service extends far beyond lifting and shifting workloads into the cloud or refactoring an application. FusionStorm helps customers build business platforms that focus on the infrastructure and operations in the public, private or hybrid-cloud, while considering all the nuance of a cloud transformation from connectivity, to the mobile workforce, to the edge. We do this by leveraging deep subject matter expertise in each area of the stack that allows us to design, build, deliver and operate a transformative and complete business solution.

Customers are now enabled and free to focus on their core business rather than on the designing, procuring, building, delivering and operating the underlying infrastructure. Customers can focus on solving business problems and changing the world.

This market is not about on-prem vs off-prem, it’s not about the public, private or hybrid cloud. It’s about focus, agility, and elasticity; it’s about enabling the innovation of game-changing technologies; it’s about speeding time to market for technologies that are consumer-facing; it’s about the realization that the number of new market entrants and disruptive technologies is unprecedented; it’s about realizing that the infrastructure barrier has been removed and anyone with a good idea can compete; it’s about creating the room to fail, the ability to expand, contract and pivot on demand to satisfy an evolving consumer condition; it’s about focusing and aligning human capital with the organizational purpose.
To close out my thoughts in the context of why, how and what regarding FusionStorm and OVHcloud.
Why?
- The “Technology Superpowers” are Cloud, Mobile, AI/ML and Edge/IoT. Calculating kVA and BTUs, racking and stacking components, performing structured cabling, OS loads, patching, waking up at 3 AM to replace a failed component or restart a service, managing RMAs and logistics are not on the superpower list and there is a good reason.
- If the metal provides the competitive advantage then you will build. E.g. – Cloud providers, these could be SaaS providers, CDN providers, etc… may opt to build their own cloud. These hyperscale customers will have bespoke designs, they will need someone to manage the supply change, perform zero defect builds against a defined specification, manage logistics, etc… While these organization may own and operate their own cloud I would argue they probably will not want to be a cloud builder, at least not at the physical metal and low-level logical level. FusionStorm can help here.
- If the infrastructure is a commodity on which you run your core business, I believe you will look to the cloud. If you run legacy applications, if you have no plans to refactor applications, no need for auto-scaling, etc… you will still have the need to exit the data center business, maybe not today or tomorrow, but a decision will need to be made on where to focus finite resources, and building and maintaining data centers and infrastructure operations will not likely be the choice. This represents a massive segment of the market, a segment that FusionStorm and OVHcloud have a great solution for.
- When it comes to virtualized workloads, it is estimated that VMware has a 75% market share regardless of market segment or sector. The quickest path to lift-and-shift is to move workloads without transforming them. Customers can experience the agility and elasticity of the cloud without the risk. Trust a skilled partner like FusionStorm, OVHcloud a VMware Cloud Verified partner with 28 global data centers and VMware the platform you know and trust to simplify, accelerate and de-risk your cloud transformation.
- FusionStorm and OVHcloud can deliver the right balance of cost and capability.
- As a FusionStorm and OVHcloud customer, you can focus on your core business and change the world. Knowing that an experienced organization has delivered the right design and is operating your infrastructure so you can focus on what matter most, all this backed by OVHcloud a leader in the IaaS space.
How?
- FusionStorm will work with your organization to understand requirements and design a public or hybrid cloud infrastructure powered by OVHcloud an industry leading IaaS cloud platform that can accommodate virtualized and bare metal workloads. These workloads can be production workloads, they can be dev/test workloads, they can be disaster recovery workloads. If you can envision it we can help you design, build, deliver and operate it.
- FusionStorm will help your organization seamlessly migrate workloads to OVHcloud taking into consideration all the aspects of a cloud transformation, not just workload migration. Everything from migrating the workloads, connectivity and user experience.
What?
- A fully managed private, public or hybrid infrastructure with increased agility and elasticity in a paradigm aimed at accelerating the cloud transformation and de-risking you, the customer.
- A pivot from CapEx to OpEx and the subscription-based economy.
- On-demand agile and elastic cloud infrastructure providing the ability to expand or contract based on need.
- Platform consistency with VMware, a platform that owns ~ 75% of the virtualization market. This means that there is no learning curve, tomorrow feels just like today with much greater agility and elasticity.
I believe that together we can accelerate cloud transformation for countless customers, delivering increased agility and elasticity and allowing them to focus on their core business. I also believe that together we can chart a course that dramatically reduces the risk associated with cloud transformation.
Finally, let me be clear, I am not anti abolishing the plastic straw. Personally, I don’t like straws, but why not just say no more straws? This is a great example of a shift driven by the purpose motive. The conspiracy theorist in me says some nascent paper straw manufacturer has a connection to a politician and there may be a financial win for someone here as well as an ecological win. One thing is for sure, there is plenty to read and debate regarding the move from plastic to paper straws.