As I sit here this Tuesday before Thanksgiving, in seat 9C on a United flight flying west to east, I am crowded and agitated by the individual sitting in seat 8C who has been trying to get their seat to lay horizontal for the last two hours (hey buddy it’s a limited recline), but thankful for the time I am afforded to ponder what was, what is and what will be. Fueled by thoughts from a meeting I am returning from and other recent conversations and encounters I’ve had over the past few weeks. This blog post is a digest of some of my thoughts and their genesis. I should note that there are a few thoughts conveyed on various topics in this post, which I tweaked over the last month. I apologize in advance for anything that may seem incoherent or disconnected.
As I sit here this Tuesday before Thanksgiving, in seat 9C on a United flight flying west to east, I am crowded and agitated by the individual sitting in seat 8C who has been trying to get their seat to lay horizontal for the last two hours (hey buddy it’s a limited recline), but thankful for the time I am afforded to ponder what was, what is and what will be. Fueled by thoughts from a meeting I am returning from and other recent conversations and encounters I’ve had over the past few weeks. This blog post is a digest of some of my thoughts and their genesis. I should note that there are a few thoughts conveyed on various topics in this post, which I tweaked over the last month. I apologize in advance for anything that may seem incoherent or disconnected.
With a National Sales Meeting (NSM) approaching and a short presentation slot to fill, I have been thinking about the best way to convey my thoughts, my vision, and a call to action. I’ve started to crystallize my ideas over the last few weeks, as I have been critically thinking through the business, what once was, what is, what will be, why, and most importantly, my reasoning. I am also thinking about some of the thoughts conveyed in a book I recently read entitled “The Everything Store: Jeff Bezos and the Age of Amazon.” In the book, the author (Brad Stone) discusses how Amazon (specifically Jeff Bezos) replaced using PowerPoint to convey ideas, instituting what has become known as the six-pager, a four-to-six-page memo/narrative. The reasoning is that PowerPoint-style presentations somehow provide permission to gloss over ideas, flatten out any sense of relative importance, and ignore the interconnectedness of ideas. I am a “narrative” sort of person; I enjoy deep thinking and conveying not only my ideas but my reasoning, my inspirations, my thoughts on potential outcomes, etc… I enjoy context, and I believe context is a critical component when trying to convey intangibles like belief, passion, and motivation. I like and respect how Amazon forces people to think deeply; far too often, we assume people will not read memos, emails, etc… We live in a world where we seem to believe cognition is assisted by attempting to get our point across using pictures and captions of 140 characters or less (lousy spelling and grammar, with the all too familiar excuse of favoring velocity of response over coherency, are a bonus). What a sad state of affairs! I am both insulted and frightened by the trend, and I expect much more. The big question is, are these the people you want to consider leaders within your organization? We need to expect more! The six-pager represents, demands, and tests everything we should expect from leadership. My presentation at this year’s NSM will be delivered via a Jupyter Notebook and will highlight innovation and try to force people to think deeply about what is possible, to take the examples provided, and to visualize what could be rather than what is. I hope this will be an interactive 30 mins, and my goal is to challenge and test the audience’s cognitive skills.
 With all of the above said, let’s move on. I believe that it is undeniable that the market is shifting in such a way that cognition may be the most critical skill for success. The ability to carry knowledge forward is diminishing; the market is moving too fast. Our ability to convert knowledge to wisdom, which aids cognition, is the difference maker. We all sell widgets of some sort; the key is how we will differentiate our widgets. I believe more than ever that differentiation requires relevant intellectual property, something you possess that no one else possesses. This intellectual property needs to be translated into a dialect our customers can understand. Articulating how our unique value adds value to our customer’s business is critical. We all operate against objectives and within constraints; this next set of thoughts will focus on my perspective on services and required decision-making.
With all of the above said, let’s move on. I believe that it is undeniable that the market is shifting in such a way that cognition may be the most critical skill for success. The ability to carry knowledge forward is diminishing; the market is moving too fast. Our ability to convert knowledge to wisdom, which aids cognition, is the difference maker. We all sell widgets of some sort; the key is how we will differentiate our widgets. I believe more than ever that differentiation requires relevant intellectual property, something you possess that no one else possesses. This intellectual property needs to be translated into a dialect our customers can understand. Articulating how our unique value adds value to our customer’s business is critical. We all operate against objectives and within constraints; this next set of thoughts will focus on my perspective on services and required decision-making.

The following attempts to outline my thoughts on service engagement types, markets, challenges, and required decisions.
Above the line
- Large-scale enterprises where professional services workflow is programmatic and sustained. These engagements, by default, fall into the as-a-service model. These accounts understand the cost of program management; they understand opportunity cost; they value quality, velocity, and on-time delivery in areas of their business that typically they would classify as context.
The potential sweet spot
- Customers with enterprise needs, but unlike large-scale enterprises who organize areas of the business as core and context, the sweet spot customer often classifies all areas of the business as core, but there are core areas of the business that are underfunded and underserved. The challenges in this space are as follows:
- Massive market segment.
- Lots of work to segment the market into those who understand that we run a “Professional Services Practice” and NOT “Professional Services Perfection.”
- Those who grasp a professional services practice understand and accept failure with the understanding that improvement is continuous and iterative.
- Those who expect perfection will be disappointed. For this segment, happiness only exists due to obfuscation and being blissfully unaware. Obfuscation is not a good strategy for developing an equitable business relationship and fostering iterative, continuous improvement. The goal should always be continuous improvement. Right?
- It is an incredible struggle to align ability with needs, desires, and expectations.
Success is measured by how quickly an engagement sitting in the “potential sweet spot” queue can be assessed and pushed above or below the line. Engagements pushed above the line are often the most successful and value-added engagements.
Below the line
- Pretty self-explanatory. Our job is to determine if there is a way to move above the line. If not today, maybe tomorrow, but given objectives and constraints, playing below the line is not an option.
Those who know me know that I like anecdotal stories. Simple stories (narratives) that dramatize a situation to create a compelling reason to think deeply. So, in this post, I will share a compelling story that made me think deeply about the idea of Everything-as-a-Service. What I will share in this post is all real, real information, real data, real anecdotes that I have used, and most importantly, a fundamental market shift.
First, let me start by outlining some business objectives:

- Linear growth
- It’s not all that exciting because 1+1=2, which means there is not much efficiency or elegance being injected into the business.
- Exponential growth
- A desirable, more interesting, and likely more efficient outcome, but not the objective.
- Combinatorial growth
- This is where we want to be. Our approach focuses on efficiency and elegance, creating the ability to do far more with far less.
While exponential growth is an acceptable trajectory, combinatorial growth remains the objective. Our desire for combinatorial growth is what will allow exponential growth to persist.
I was engaged in an opportunity a few weeks ago (update: a few months ago). An account executive asked me to have a call with a prospect to talk about a fairly complex consulting engagement. After spending about an hour on the phone with the prospect, explaining our approach, answering questions, etc… the feedback was positive, and the customer was considering moving forward with us on this consulting engagement. As always, my next step was to think about execution; how would we execute? Realizing that placing myself on the project was impossible, I crafted an engagement model, identified the resources, engagement cadence, timeframe, etc… and started the wheels in motion to align these things to reduce risk and increase the probability of a successful engagement. This engagement had a finite scope, a reasonably clear set of requirements, a finite timeframe, etc… Fast forward a few weeks (update: a couple of months), and we are many revisions of a proposal later, and it has become a questionable deal, distracting and probably not worth doing. Why?
- Unbalanced engagement model.
- The carrot is being oversold.
- While future opportunities should be considered, an engagement must stand on its merits. If not, the probability of success is dramatically lowered, and the quid pro quo is easily escaped due to lack of quality delivery; all the while, this was the system that was created from the onset.
- Scope creep.
- What starts as a well-defined and finite scope shifts to a Maytag repairman model with an open-ended T&M scope.
- The facade of a commitment and an expectation is created.
- A purchase order creates an implied commitment, but in reality, there’s no commitment by any of the parties involved.
- Misalignment of expectations is becoming increasingly apparent.
- A feeling of ownership, a supplier/buyer relationship rather than a partnership, permeates the air.
I believe Everything-as-a-Service (XaaS) has become the trend. When I say trend, I’m implying trending towards the standard, if not already there.
Let me share some anecdotes across a variety of markets (outside tech) that I believe support my belief:
 Landscape professionals. My lawn care company shows up for a mow and leaf cleanup every Friday. They require a contract, they require that the contract is for the entire season, and they are rigid on the day of the week they provide (e.g., I get a coveted Friday mow, which took me years to get). If I want something different, there are no hard feelings; my landscaper is just the wrong guy.
Landscape professionals. My lawn care company shows up for a mow and leaf cleanup every Friday. They require a contract, they require that the contract is for the entire season, and they are rigid on the day of the week they provide (e.g., I get a coveted Friday mow, which took me years to get). If I want something different, there are no hard feelings; my landscaper is just the wrong guy.

Pool service. I have a pool service; they provide chemicals, clean my pool weekly, etc… The pool service requires a contract for the season; they visit each week, and often, the pool is clean, but the billing remains the same.
OK, let’s move up the stack a bit:
 About ten years ago, I had pneumonia, I was walking around with it for a year or so, and it was pretty bad and in both my lungs. I was hit so hard that I passed out in Penn Station, made it home on the train, and landed in the hospital for over a week while they figured out what was wrong with me. The internal medicine doctor who finally diagnosed me was excellent and remained my primary care physician for three or four years. One day, I got a letter saying they are shifting the practice to a membership-required practice. For $2,500 a year (that was then), I could buy into the practice; if I did not want to pay the $2,500 a year, that was OK, and they would wish me luck in my search for a new primary care physician. With managed healthcare erosion impacting service quality, this doctor wanted patients who valued high-quality care, and he was not afraid to put faith in his value, to expose what was occurring in the industry and the constraints he needed to work within, he went as far as to hold seminars for patients so they could understand the why. Sure, he lost some patients, but in the end, he moved upstream to service patients (customers) with a higher quality of service.
About ten years ago, I had pneumonia, I was walking around with it for a year or so, and it was pretty bad and in both my lungs. I was hit so hard that I passed out in Penn Station, made it home on the train, and landed in the hospital for over a week while they figured out what was wrong with me. The internal medicine doctor who finally diagnosed me was excellent and remained my primary care physician for three or four years. One day, I got a letter saying they are shifting the practice to a membership-required practice. For $2,500 a year (that was then), I could buy into the practice; if I did not want to pay the $2,500 a year, that was OK, and they would wish me luck in my search for a new primary care physician. With managed healthcare erosion impacting service quality, this doctor wanted patients who valued high-quality care, and he was not afraid to put faith in his value, to expose what was occurring in the industry and the constraints he needed to work within, he went as far as to hold seminars for patients so they could understand the why. Sure, he lost some patients, but in the end, he moved upstream to service patients (customers) with a higher quality of service.
Let’s look at another medical example. My wife needed Mohs surgery years ago; she went to a doctor who took no insurance, who was very expensive, who was backlogged for months, yet this doctor is thriving.
Let’s look at a so-called T&M business model. How about the auto repair industry?

Anyone who knows how this industry works will know that auto mechanics use what are known as Chilton rates to quote jobs. E.g., Front breaks on a 1979 Pinto is four hours of labor at N rate. What’s important here is that the average mechanic can perform these jobs in 1/4th the time, but the Chilton guide sets the standard, and efficiency is rewarded.
I went further, racking my brain to think about the viable time and material (T&M) business.
Some might say that software developers work on a T&M basis. In this case, I would say the T&M protects the developer from scope creep and the reality that in an Agile model, the scope will change. The scope and timeframe are understood and defined, dollars are allocated to each sprint/milestone, and yes, this maps back to complexity (story points) and/or required level-of-effort, but the goal is to execute against the milestone and track burndown against the estimations.

As a parent, babysitting popped into my head.
Even my babysitter metrics opportunity cost and expects an equitable supplier and buyer relationship. When paying their babysitter, what sort of person rounds down to the nearest hour? I remember going out with my wife when my kids were young, being tired and ready to go home, and debating whether we had been out long enough to make the babysitting engagement valuable to the babysitter. The 17-year-old babysitter had an opportunity cost that I needed to consider; a 17-year-old gave up their Friday night, but they expected to work the night. This dialog only happened because we valued our children and the babysitter; I was sleepy, so we would go home and pay for two hours we didn’t use.

Now, how about that Maytag repairman? They are not even T&M any longer. The Maytag repairman is associated with appliance repair. Let’s look at how people do appliance repair:
- Manufacturer Warranty
- Fixed cost baked into the price of the new purchase for some period. Highly predictable model.
- Extended warranty services, like an American Home Shield (AHS).
- Large-scale break-fix operations like this require an insurance plan with a premium and a deductible for each service incident.
My point here is you can’t even get the Maytag repairman in the Maytag repairman model anymore.
Finally, let’s explore an anecdote about implied commitment and expectations:
 I live and work in the New York metro area; there is a common practice of street vendors who sell umbrellas when it rains at exponentially higher prices, simple supply and demand economics. Imagine that the cost of these cheap umbrellas on a sunny day is $2, but when it rains, New Yorkers are willing to pay $10. Now imagine walking out to the street vendor with an IOU for $100 bucks and telling the vendor I am committed to them. In this case, I am providing nothing more than an IOU with an expectation that my intent to buy an umbrella from them in the future (at the height of demand, BTW) entitles me to be able to buy the umbrella for $2 (50 umbrellas @ $2). In return, my carrot is I will tell my friends that this vendor has quality umbrellas. What response do you think I would receive? It’s probably very similar to my response to many deals I look at: “WTF are you talking about?”
I live and work in the New York metro area; there is a common practice of street vendors who sell umbrellas when it rains at exponentially higher prices, simple supply and demand economics. Imagine that the cost of these cheap umbrellas on a sunny day is $2, but when it rains, New Yorkers are willing to pay $10. Now imagine walking out to the street vendor with an IOU for $100 bucks and telling the vendor I am committed to them. In this case, I am providing nothing more than an IOU with an expectation that my intent to buy an umbrella from them in the future (at the height of demand, BTW) entitles me to be able to buy the umbrella for $2 (50 umbrellas @ $2). In return, my carrot is I will tell my friends that this vendor has quality umbrellas. What response do you think I would receive? It’s probably very similar to my response to many deals I look at: “WTF are you talking about?”
None of these service models or anecdotes should be challenging to grasp. To deliver quality services, predictability is required; costs are predictable; thus, revenue streams need to be predictable. To provide quality service delivery, you must staff using a predictable revenue stream, harden schedules, resource allocation, etc… If you can’t, service delivery problems, unhappy customers, etc… are a foregone conclusion. Accommodation is not a strategy for quality delivery or survival.
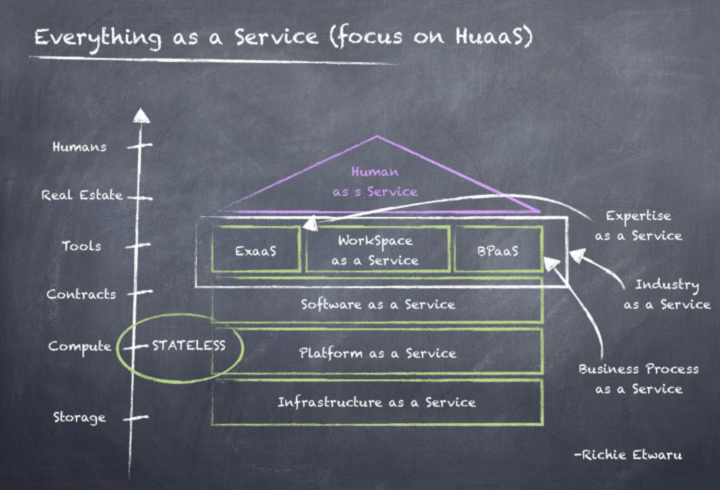
Everything-as-a-Service is real and powered by Humans-as-a-Service (HuaaS). Given the finite nature of the human species, we’ve begun leveraging automation (call it ML/DL/AI or just old-fashioned automation) to create value beyond viewing HuaaS as just another widget. To create value, finite resources must be applied to high-yield investments. This will always mean that decisions will continuously need to be made on where to focus, and these decisions may differ from day to day as conditions change. Doing things faster, with greater accuracy, with less risk, etc… requires intellect. The shift from a 100:1 time to value (TtV) ratio to a 1:100 TtV ratio is at the heart of the knowledge economy. The economic principles of an industrial economy cannot be applied to a knowledge economy.