
In the interest of benchmarking de-duplication rates with databases I created a process to build a test database, load test records, dump the database and perform a de-dupe backup using EMC Avamar on the dump files. The process I used is depicted in the flowchart below.
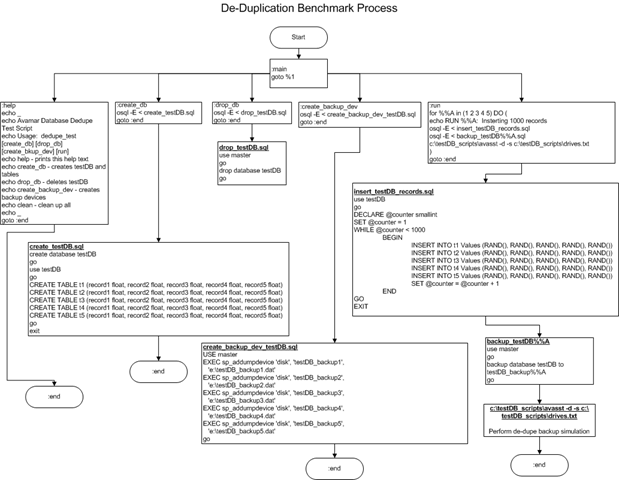
1. Create a DB named testDB
2. Create 5 DB dump target files – testDB_backup(1-5)
3. Run the test which inserts 1000 random rows consisting of 5 random fields for each row. Once the first insert is completed a dump is performed to testDB_backup1. Once the dump is complete a de-dupe backup process is performed on the dump file. This process is repeated 4 more times each time adding an additional 1000 rows to the database and dumping to a new testDB_backup (NOTE: this dump includes existing DB records and the newly inserted rows) file and performing the de-dupe backup process.
Once the backup is completed a statistics file is generated showing the de-duplication (or commonality) ratios. The output from this test is as follows:

You can see that each iteration of the backup shows an increase in the data set size with increasing commonality and de-dupe rations. This test shows that with 100% random database data using a DB dump and de-dupe backup strategy can be a good solution for DB backup and archiving.